A crucial phase in the data science lifecycle, data preprocessing has a direct effect on the caliber of insights and machine learning model performance. Because raw data is frequently noisy, inconsistent, or incomplete when it is first acquired, it must undergo several preprocessing stages before it can be used for analysis. This manual examines several data preparation methods, their significance, methods, resources, and practical uses.
Why Data Preprocessing is Important
Data preprocessing ensures that raw data is transformed into a clean, structured format for accurate analysis and model training. Models may produce inaccurate predictions without preprocessing due to anomalies, missing values, or irrelevant features.
Key Benefits of Data Preprocessing:
- Improves Model Accuracy: Clean, standardized data ensures better model performance.
- Reduces Complexity: Simplifies data to enhance computational efficiency.
- Handles Data Issues: Addresses missing values, outliers, and inconsistencies.
- Optimizes Features: Enhances the relevance of variables used in analysis.
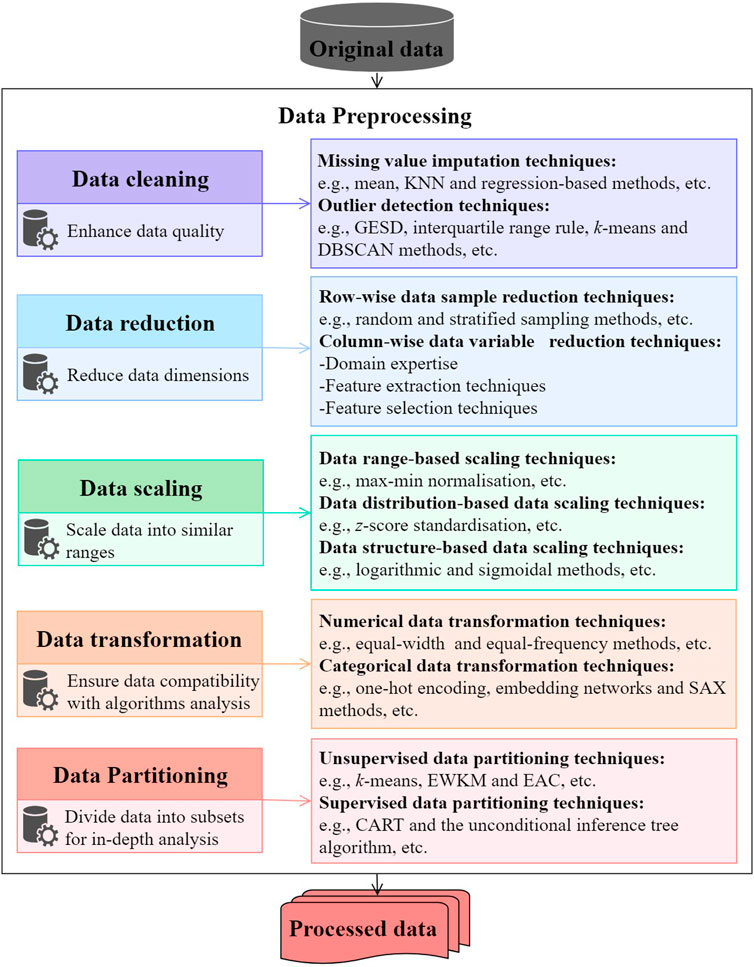
Core Approaches for Preprocessing Data
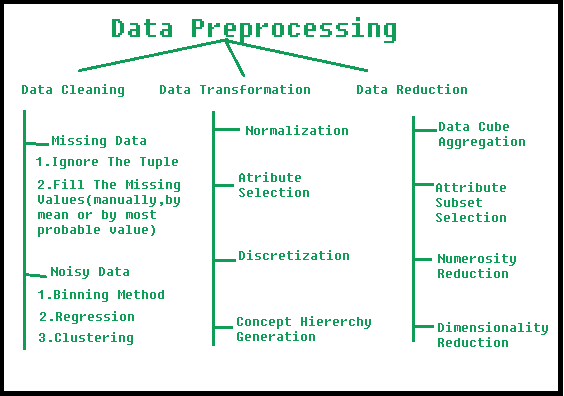
Source: https://www.geeksforgeeks.org/data-preprocessing-in-data-mining/
Credits: geeksforgeeks.org*
1. Data Cleaning
Data cleaning involves identifying and correcting errors, inconsistencies, and inaccuracies in the dataset.
- Techniques:
- Handling Missing Values: Impute missing values with mean, median, or mode.
- Removing Duplicates: Eliminate duplicate rows or columns.
- Correcting Errors: Identify and fix incorrect entries (e.g., negative age values).
Example:
import pandas as pd
data = pd.read_csv(‘dataset.csv’)
data.fillna(data.mean(), inplace=True) # Filling missing values with mean
2. Data Integration
When data is collected from multiple sources, integration ensures consistency and completeness.
- Techniques:
- Schema Matching: Align schemas from different databases.
- Data Merging: Combine datasets with similar attributes.
- Data Deduplication: Remove redundant data entries.
- Use Case:
- Merging customer data from CRM and website analytics platforms.
3. Data Transformation
Transformation involves converting data into a suitable format for analysis.
- Techniques:
- Normalization: Scales data to a range of 0 to 1.
- Standardization: Rescales data with a mean of 0 and standard deviation of 1.
- Encoding Categorical Variables: Converts categories into numerical values using one-hot or label encoding methods.
Example:
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
normalized_data = scaler.fit_transform(data[[‘column_name’]])
4. Data Reduction
Data reduction minimizes the volume of data while retaining its essential information.
- Techniques:
- Dimensionality Reduction: Use methods like PCA (Principal Component Analysis) to reduce the number of features.
- Feature Selection: Identify and retain the most important variables.
- Sampling: Reduce data size by selecting a representative subset.
- Use Case:
- Simplifying datasets with hundreds of features for faster processing.
5. Data Discretization
Discretization converts continuous variables into discrete categories or bins.
- Techniques:
- Equal-Width Binning: Divides data into bins of equal range.
- Equal-Frequency Binning: Ensures each bin has the same number of records.
- Example:
- Grouping customer ages into categories like 18-25, 26-35, etc.
6. Feature Engineering
Feature engineering involves creating new features or modifying existing ones to improve model performance.
- Techniques:
- Polynomial Features: Generate higher-order features.
- Interaction Features: Combine multiple variables.
- Date-Time Features: Extract year, month, or day from timestamp data.
- Use Case:
- Deriving “day of the week” from transaction timestamps to analyze shopping patterns.
Comparison of Preprocessing Techniques
| Approach | Purpose | Advantages | Limitations |
| Data Cleaning | Correct errors and inconsistencies | Improves data quality | Can be time-consuming |
| Data Transformation | Standardize and normalize data | Makes data suitable for models | May oversimplify data |
| Data Reduction | Reduce data size | Speeds up processing | May lose important details |
| Feature Engineering | Enhance feature set | Boosts model performance | Requires domain expertise |
Tools for Preprocessing Data
For beginners and professionals, these tools simplify preprocessing tasks:
| Tool | Purpose | Features |
| Pandas | Data manipulation | Missing value handling, filtering, merging |
| scikit-learn | Machine learning preprocessing | Normalization, encoding, scaling |
| OpenRefine | Data cleaning | Handle messy datasets |
| NumPy | Numerical computations | Efficient array operations |
| RapidMiner | Visual data preparation | Drag-and-drop interface |
Best Practices for Data Preprocessing
1. Understand Your Data
- Explore the dataset using descriptive statistics and visualization.
- Identify missing values, outliers, and inconsistencies.
2. Automate Preprocessing Steps
- Use scripts to automate repetitive tasks like normalization and encoding.
- Example: Automating scaling for all numerical columns.
3. Validate Results
- Check preprocessed data for accuracy and consistency.
- Example: Ensure categorical encoding doesn’t introduce errors.
4. Document Changes
- Maintain a record of preprocessing steps for reproducibility.
Challenges in Data Preprocessing
| Challenge | Description | Solution |
| Missing Data | This leads to incomplete analysis | Use imputation techniques |
| Imbalanced Data | Skews machine learning results | Apply oversampling or undersampling |
| High Dimensionality | Slows down computations | Use dimensionality reduction |
| Noise in Data | Reduces model accuracy | Use smoothing techniques |
Real-World Example: Preprocessing for Retail Sales Prediction
Objective:
Predict future sales based on historical data.
Steps:
- Data Cleaning:
- Filled missing sales values with the monthly average.
- Data Transformation:
- Standardized sales and promotional variables.
- Feature Engineering:
- Extracted day-of-week and holiday indicators from timestamps.
- Data Reduction:
- Used PCA to reduce the feature set from 20 to 10 variables.
Outcome:
- Improved model accuracy by 15% after preprocessing.
Future Trends in Data Preprocessing
1. AI-Powered Preprocessing
- Automated feature engineering and cleaning with AI tools.
2. Real-Time Preprocessing
- Handling streaming data from IoT devices and live feeds.
3. Ethical Preprocessing
- Adhering to privacy regulations and ensuring unbiased data preparation.
Conclusion: The Foundation of Effective Data Analysis
Preprocessing is the cornerstone of good data analysis and machine learning, not only a preparatory step. Data scientists may make sure their models operate at their best and provide insightful results by becoming proficient in preprocessing techniques.
Every preprocessing phase is essential to the data science workflow, whether you’re lowering dimensionality, cleaning data, or engineering features. To become an expert in this crucial area of data science, start with modest datasets, try out tools like scikit-learn and pandas, and hone your abilities