If you want to gather valuable insights from Reddit without spending hours scrolling, Redscraper.io is the tool you need. Imagine quickly collecting posts and comments from any subreddit, all in one place, ready for your analysis or projects.
Whether you’re a marketer, researcher, or just curious, Redscraper. io makes scraping Reddit simple and fast. Keep reading to discover how you can save time and get the data you want with just a few clicks.
What Is Redscraper.io
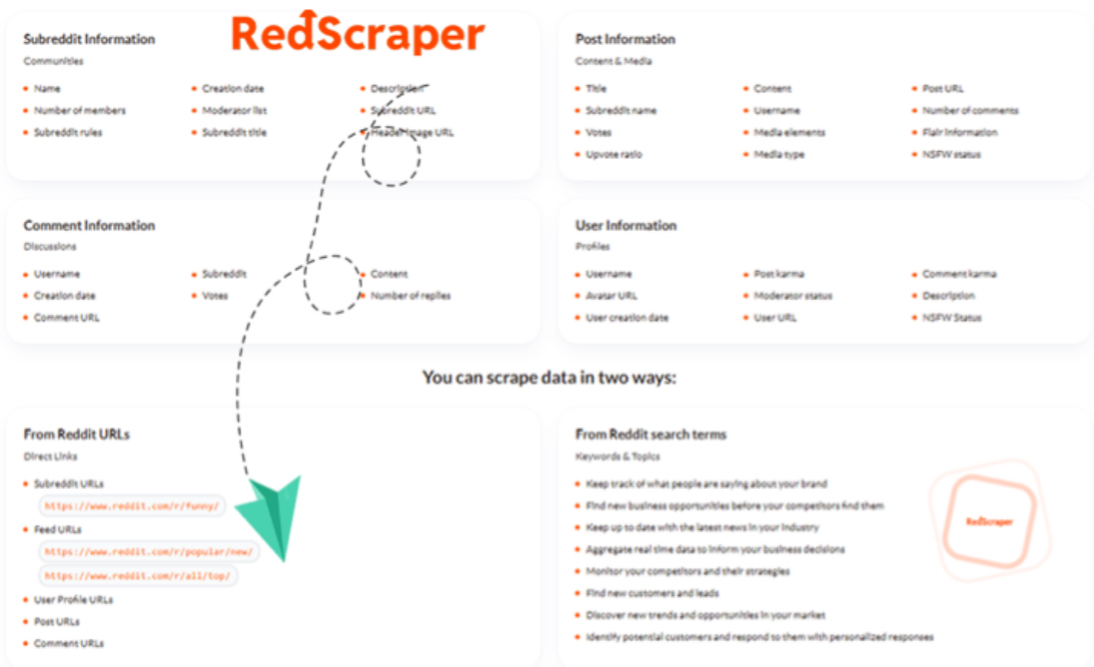
RedScraper.io is a simple tool to scrape Reddit posts and comments quickly. It helps collect data from Reddit without coding skills. This tool is useful for researchers, marketers, and anyone who needs Reddit data for analysis or content creation. With RedScraper.io, users can save time and get accurate results from Reddit’s vast community.
What Is Redscraper.io?
Reddit scraper is an online platform designed to extract Reddit posts and comments. It works by gathering data from specific subreddits, users, or keywords. The tool presents the information in an easy-to-read format. It supports various export options like CSV and JSON for further use.
- Easy to use: No programming needed. Just enter your search terms.
- Fast scraping: Collects data quickly from multiple Reddit threads.
- Custom filters: Filter by date, subreddit, or type of content.
- Export options: Download data in CSV or JSON formats.
- Comment scraping: Extracts comments along with posts.
How Does Redscraper.io Work?
- Input a subreddit, keyword, or user name in the search box.
- Select filters like date range or post type.
- Click the scrape button to start the process.
- View the results displayed on the screen.
- Download the data file for your use.
Who Can Benefit From Reddit Scraper?
| User Type | Use Case |
| Researchers | Analyze social trends and discussions. |
| Marketers | Find customer opinions and product feedback. |
| Content Creators | Gather ideas and community insights. |
| Developers | Test Reddit data in apps and tools. |
Key Features Of Redscraper.io
RedScraper.io is a powerful tool designed to help users scrape Reddit posts and comments quickly and easily. It offers a range of features that simplify data collection from Reddit, making it accessible to everyone. The key features of Reddit scraper focus on efficient data extraction, ease of use, flexible export formats, and detailed filtering options. These features make it an excellent choice for researchers, marketers, and content creators who need Reddit data for analysis or projects.
Post And Comment Extraction
RedScraper.io specialises in extracting both posts and comments from Reddit with precision. It can pull data from any subreddit or user profile, gathering detailed information such as post titles, content, timestamps, and the number of upvotes. The tool also captures nested comments and replies, ensuring no valuable data is missed.
This feature supports:
- Extraction of posts with metadata like author name and post date.
- Collection of all comments and replies within a thread.
- Ability to handle large volumes of data in a single run.
Data is gathered in a structured format, making it easy to analyze. The tool uses fast scraping technology to reduce wait times. Here is a simple example of the data fields collected:
| Data Type | Description |
| Post Title | The headline or topic of the Reddit post |
| Post Content | The main body or text of the post |
| Author | Username of the person who created the post or comment |
| Timestamp | Date and time when the post or comment was made |
| Upvotes | Number of upvotes received |
| Comments | All replies under each post with their details |
User-friendly Interface
RedScraper.io offers a simple and clean interface that anyone can use. The design focuses on making the scraping process smooth and straightforward. Users do not need coding skills or technical knowledge to operate the tool effectively.
The interface features:
- Clear input fields to enter subreddit names or user profiles.
- Step-by-step guidance for setting up scraping tasks.
- Real-time progress indicators showing the scraping status.
- Easy access to help and support resources.
The dashboard groups all key functions together, making it easy to navigate. Buttons and menus use plain language, avoiding technical jargon. The layout adapts to different devices, including tablets and smartphones, so users can scrape data anywhere.
Here is a list of interface benefits:
- Intuitive controls reduce learning time.
- Minimal clicks to start data extraction.
- Visual feedback helps track ongoing processes.
- Simple error messages to fix issues quickly.
Data Export Options
After scraping Reddit, RedScraper.io lets users export the collected data in multiple formats. This flexibility suits different needs like data analysis, reporting, or importing into other software.
Supported export formats include:
- CSV – Easy to open in Excel or Google Sheets for analysis.
- JSON – Ideal for developers needing structured data.
- Excel – Useful for advanced spreadsheet work.
- TXT – Plain text for simple record keeping.
Each export file contains all scraped details such as posts, comments, authors, and timestamps. Users can select the format before starting the export process.
Here is an example of how export options appear:
Choose Export Format: – CSV – JSON – Excel – TXT
Export speed is optimized for large datasets, allowing quick downloads. RedScraper.io also supports scheduled exports, which automatically save data at set times. This feature helps users keep their datasets up to date without manual work.
Customizable Filters
RedScraper.io includes powerful filters that let users narrow down the data they want to collect. Customizable filters improve scraping efficiency and focus on relevant content only.
Common filtering options include:
- Time Range: Scrape posts and comments from a specific date or period.
- Keyword Filters: Include or exclude posts containing certain words or phrases.
- Subreddit Selection: Choose one or multiple subreddits to target.
- User Filters: Extract posts or comments from specific Reddit users.
- Post Type: Filter by text posts, images, videos, or links.
Filters work in combination to create precise scraping criteria. This reduces unnecessary data and saves time during extraction.
Custom filters help users get exactly the Reddit data they need for research, content creation, or market analysis.
Setting Up Redscraper.io
Setting up RedScraper.io is the first step to start scraping Reddit posts and comments quickly and efficiently. This tool offers a simple way to collect data from Reddit without complex coding. The setup process involves creating an account, accessing the API, and installing the necessary components. Each step is straightforward and designed for users with any level of technical skill. Follow the guide below to get RedScraper.io ready for your data projects.
Account Creation
Creating an account on RedScraper.io is simple and fast. A user account lets you access the dashboard, manage your scraping projects, and monitor your API usage.
- Visit the RedScraper.io homepage and click on the “Sign Up” button.
- Fill in your email address, choose a secure password, and enter your username.
- Confirm your email through the verification link sent to your inbox.
Once your account is active, you can log in to the dashboard. The dashboard shows:
| Feature | Description |
| Project Management | Create and organize your scraping tasks |
| API Usage Stats | Track the number of requests made and limits |
| Billing Information | View subscription and payment details |
Api Access
API access is the key to using RedScraper.io’s scraping features. The API allows your applications to request data from Reddit through RedScraper.io.
After account creation, follow these steps to get your API key:
- Log in to your Reddit scraper account.
- Navigate to the API Access section in the dashboard.
- Click on Generate New API Key.
- Copy the generated key and keep it safe.
The API key works like a password for your apps. Never share it publicly. Use it in your code to authenticate requests.
API limits depend on your subscription plan. Here’s a quick overview:
| Plan | Requests per Minute | Monthly Quota |
| Free | 10 | 5,000 |
| Basic | 50 | 50,000 |
| Pro | 200 | 200,000 |
Use the API documentation for detailed instructions on request formats and response handling.
Installation Steps
Installing RedScraper.io tools is quick. Follow these steps to prepare your system for scraping Reddit data.
- Check Requirements: Ensure your system has Python 3.6+ installed.
- Install RedScraper SDK: Open your terminal or command prompt and run:
pip install redscraper
- Configure API Key: After installation, set your API key as an environment variable:
export REDSCRAPER_API_KEY=’your_api_key_here’ For Linux/Mac set REDSCRAPER_API_KEY=your_api_key_here For Windows
- Test Installation: Run a simple test script to verify:
from redscraper import RedScraper scraper = RedScraper() posts = scraper.get_posts(‘learnpython’, limit=5) print(posts)
If the script returns recent posts, installation is successful. Troubleshoot by checking internet connection and API key validity.
Tips for smooth setup:
- Use a code editor like VS Code or PyCharm for easier script writing.
- Keep your API key secure and do not hard-code it in shared scripts.
- Read the RedScraper.io documentation for advanced setup options.
How To Scrape Reddit Posts
Scrape Reddit Posts And Comments Easily With Redscraper makes gathering data from Reddit quick and simple. Knowing how to scrape Reddit posts helps you collect useful information for research, marketing, or personal projects. This guide breaks down the process into clear steps. Follow along to start scraping posts effectively.
Selecting Subreddits
The first step is choosing the right subreddits. Subreddits are communities focused on specific topics. Picking relevant ones ensures you get the data you need.
Consider these points when selecting subreddits:
- Relevance: Choose subreddits that match your topic or interest.
- Activity Level: Pick subreddits with regular posts and comments for fresh data.
- Size: Larger subreddits have more content, but smaller ones may offer niche insights.
Use Redscraper.Io’s interface to add multiple subreddits at once. Separate each subreddit by commas or list them in the input box. For example:
technology, science, gadgets
Redscraper.io supports both popular and lesser-known subreddits. You can also scrape posts from private subreddits if you have access.
| Subreddit Type | Best For | Example |
| Large | Broad topics, trending content | r/news, r/funny |
| Medium | Specific interests, active engagement | r/photography, r/coding |
| Small | Niche topics, detailed discussions | r/vintageaudio, r/minimalism |
Applying Search Filters
Search filters narrow down the posts you want to scrape. Redscraper.io offers many options to refine your search.
Common filters include:
- Keywords: Enter specific words or phrases to find relevant posts.
- Date Range: Set start and end dates to limit posts by time.
- Post Type: Choose between posts, comments, or both.
- Sort Order: Sort by newest, hottest, or top posts.
- Minimum Upvotes: Filter posts by popularity.
Example filter settings:
| Filter | Value | Effect |
| Keyword | “electric cars” | Find posts mentioning electric cars |
| Date Range | 01-01-2024 to 03-31-2024 | Posts from first quarter 2024 |
| Sort Order | Top | Most popular posts first |
Applying filters helps save time and avoids collecting irrelevant data. Combine several filters for best results.
Running The Scraping Process
After selecting subreddits and applying filters, start the scraping process. Redscraper.Io makes this step easy and user-friendly.
Follow these steps:
- Review your subreddit list and filters.
- Click the “Start Scraping” button.
- Monitor progress on the screen. Redscraper.io shows how many posts and comments are collected.
- Pause or stop the process anytime if needed.
- Once done, download the data in formats like CSV or JSON.
Tips for smooth scraping:
- Ensure a stable internet connection.
- Use smaller batches for large subreddits to avoid timeouts.
- Check API limits if scraping large volumes.
Reddit scraper handles all behind-the-scenes work. Focus on analysing your data once the scraping finishes.
Extracting Comments Efficiently
Scraping Reddit posts and comments is a great way to gather insights, opinions, and trends. Redscraper.io simplifies this task, especially when it comes to extracting comments efficiently. Comments often hold valuable details that posts alone don’t show. Extracting them properly requires careful handling of Reddit’s structure. Redscraper.io offers tools to navigate, manage, and save comments with ease. This section explains how to extract comments smoothly, making your data collection cleaner and faster.
Navigating Comment Threads
Reddit comments form threads where users reply to each other. These threads can be long and complex. Redscraper.io helps you move through these threads step-by-step. It maps out the comment flow clearly.
- Sequential Access: Redscraper.io lets you access comments in the order they appear.
- Thread Breakdown: View comments by level, from top-level to deep replies.
- Filter Options: Choose to scrape only certain types of comments, like the most upvoted or recent ones.
Using these features saves time and avoids missing important comments. It also reduces noise from irrelevant or deleted comments. The platform shows comment metadata like author, time, and score, helping you sort and analyze data fast.
| Feature | Benefit |
| Thread Mapping | Visualizes comment hierarchy for easy navigation |
| Comment Filters | Focus on valuable comments only |
| Metadata Access | Enables detailed sorting and analysis |
Handling Nested Comments
Reddit comments often nest inside each other, creating layers of replies. Handling these nested comments correctly is crucial for accurate data. Redscraper.io automatically recognizes and organizes these layers.
Nested comments can be tricky. A simple scraper might mix up parent and child comments. Reddit scraper avoids this by:
- Identifying Comment Levels: Each comment gets a level number showing its depth.
- Maintaining Parent-Child Links: The tool keeps track of which comment replies to which.
- Collapsing and Expanding: You can expand nested replies or collapse them for a cleaner view.
This structure helps in:
- Analysing conversations accurately
- Tracking user interactions
- Building datasets that keep the comment context
Handling nested comments properly ensures your data reflects real discussions without confusion or loss.
Saving Comment Data
Once comments are scraped, saving them correctly is important. Redscraper.io offers multiple formats for storing comment data. This flexibility helps match your project needs.
Popular formats include:
- CSV: Easy for spreadsheets and basic analysis
- JSON: Good for preserving nested structures and complex data
- Excel: Useful for business reporting and sharing
Redscraper.io also supports custom field selection. You can choose which data to save, such as:
- Comment text
- Author name
- Timestamp
- Upvotes
- Parent comment ID
Saving only the needed fields keeps files smaller and easier to work with. The platform also allows batch downloading for large datasets.
| Format | Best Use | Advantages |
| CSV | Simple data tables | Easy to open in spreadsheet apps |
| JSON | Complex nested data | Preserves comment hierarchy |
| Excel | Business reports | Supports formulas and charts |
Smart saving options make the comment data ready for analysis, visualization, or sharing with others.
Managing And Exporting Data
Managing and exporting data from Reddit posts and comments is a key step after scraping with Redscraper.io. Proper data handling helps you organize, analyze, and share the information efficiently. Redscraper.io offers flexible options to manage your scraped data, ensuring it fits your needs. You can save data in various formats and export it easily for further use. This section explains how to handle data formats, export options, and how to connect Redscraper.io with other software tools.
Data Formats Supported
Redscraper.Io supports multiple data formats to store Reddit posts and comments. This flexibility lets you choose the best format for your project or tool. The main data formats include:
- CSV (Comma-Separated Values): Ideal for spreadsheets and simple data tables.
- JSON (JavaScript Object Notation): Good for hierarchical data and programming use.
- Excel (XLSX): Useful for advanced data analysis in Microsoft Excel.
- Plain Text: Basic format for quick reviews or simple storage.
Each format serves different needs. For example, CSV is easy to open in Excel or Google Sheets. JSON works well for developers who want to process data with code. Excel files allow you to use formulas and charts directly. Plain text files are lightweight and easy to read.
| Format | Best For | Key Features |
| CSV | Spreadsheets, simple tables | Easy to open, widely supported |
| JSON | Developers, APIs | Structured data, easy to parse |
| XLSX | Advanced Excel analysis | Supports formulas and charts |
| Plain Text | Quick review, lightweight storage | Readable, minimal formatting |
Choosing the right format depends on your workflow. Redscraper.Io makes it easy to select and switch between formats to match your project needs.
Exporting To Csv And Json
Exporting scraped Reddit data is simple with Redscraper.Io. CSV and JSON are the two most popular export formats available. Each serves different purposes and offers unique advantages.
CSV export creates files that store data in rows and columns. This format is perfect for viewing in spreadsheet apps like Excel or Google Sheets. CSV files allow you to sort, filter, and analyze data quickly.
JSON export saves data in a structured format. This is useful for developers and programmers. JSON files keep the relationships between posts and comments clear. They are easy to import into databases or use in coding projects.
Exporting data with Redscraper.Io happens in a few easy steps:
- Choose the data you want to export (posts, comments, or both).
- Select the export format (CSV or JSON).
- Click the export button to download the file.
Both CSV and JSON files are compatible with many tools, making data sharing simple. Redscraper.io also ensures the exported data is clean and well-structured. This reduces the need for extra formatting after export.
| Export Feature | CSV | JSON |
| File Type | Text, comma-separated | Text, structured key-value pairs |
| Best Use | Spreadsheets, manual review | Programming, APIs, databases |
| Data Structure | Flat rows and columns | Nested objects and arrays |
| Ease of Use | Easy to open and edit | Requires programming to parse |
Integrating With Other Tools
Redscraper.Io lets you connect your scraped Reddit data with various other tools. This integration helps to automate workflows and extend data use.
Common integrations include:
- Data Analysis Software: Import CSV or JSON files into Excel, Google Sheets, or Power BI for deeper insights.
- Programming Languages: Use JSON data with Python, JavaScript, or R to build custom applications or data models.
- Database Systems: Upload JSON or CSV files into MySQL, MongoDB, or PostgreSQL for storage and querying.
- Automation Platforms: Connect with Zapier or Integromat to trigger actions based on new scraped data.
Integration is easy because Redscraper.Io provides clean and standardized data formats. Many tools support CSV and JSON natively, so you avoid complex conversions.
Example: Use Python to load JSON data from Redscraper.Io with just a few lines of code.
import json with open(‘reddit_data.json’, ‘r’) as file: data = json.load(file) print(data[0][‘post_title’])
This code snippet reads a JSON file and prints the title of the first post. Similar examples work for other programming languages.
Integrations save time and increase productivity. They allow you to focus on analyzing and using Reddit data instead of handling file formats.
Best Practices For Ethical Scraping
Scraping Reddit posts and comments with Redscraper.io offers a fast way to gather valuable data. Ethical scraping ensures that this process respects Reddit’s rules and user privacy. Following best practices helps keep your scraping activities safe and legal. It also protects Reddit’s platform and its community. Below are key guidelines for ethical scraping to keep in mind while using Redscraper.io.
Respecting Reddit’s Terms Of Service
Reddit’s Terms of Service (ToS) set the rules for data use on their platform. Scraping Reddit without following these rules can lead to legal issues or account bans. Always review Reddit’s ToS before scraping.
Important points to remember:
- Do not collect data for spam or abuse.
- Avoid scraping personal user information.
- Use data only for allowed purposes like research or analysis.
- Comply with Reddit’s API rules if using their API.
Here is a simple table to compare allowed and disallowed scraping activities:
| Allowed Actions | Disallowed Actions |
| Collecting public posts for research | Harvesting user private messages |
| Using scraped data for personal projects | Using data to create spam or fake accounts |
| Following Reddit API guidelines | Ignoring robots.txt or rate limits |
Respecting Reddit’s ToS builds trust and avoids penalties. Ethical scraping protects your access and Reddit’s community.
Rate Limiting And Avoiding Bans
Reddit controls how often you can request data to prevent server overload. Ignoring these limits causes your IP to be banned. Use rate limiting to send requests slowly and safely.
Key tips for rate limiting:
- Set delays between each data request.
- Use randomized timing to avoid patterns.
- Monitor responses for “Too Many Requests” errors.
- Pause scraping if you detect warnings or errors.
Example of simple rate limiting in code:
for (post in posts) { scrape(post); sleep(random(1000, 3000)); // wait 1 to 3 seconds }
Following rate limits helps keep your IP safe. It reduces the chance of being banned or blocked.
Here is a quick checklist to avoid bans:
- Do not send requests too quickly.
- Respect API usage limits if using Reddit API.
- Rotate IP addresses if needed.
- Handle errors gracefully.
Careful pacing lets you scrape more data over time without interruptions.
Privacy Considerations
Reddit users share content publicly but still expect privacy in some areas. Ethical scraping respects user privacy and data protection rules.
Follow these privacy guidelines:
- Do not collect or share sensitive personal data.
- Avoid scraping private subreddits without permission.
- Remove or anonymise usernames when sharing data.
- Use the scraped data responsibly and securely.
Data privacy benefits everyone:
- Protects users from identity theft or harassment.
- Builds trust with the Reddit community.
- Keeps your project ethical and legal.
Example of anonymising data in code:
function anonymizeUsername(username) { return username.slice(0, 3) + ”; }
Always check local laws on data privacy. Treat all scraped data with care.
Common Challenges And Solutions
Scraping Reddit posts and comments with Redscraper.io can simplify data collection for your projects. Still, users face some common challenges during this process. Understanding these obstacles and their solutions helps you scrape data smoothly and efficiently. This section covers typical issues and practical fixes to keep your scraping tasks on track.
Dealing With Api Limits
Reddit sets strict API limits to control the number of requests from each user. These limits can slow down scraping or cause your tool to stop working temporarily. Redscraper.io helps manage these limits, but knowing how to handle them is key.
Common API limit challenges include:
- Request rate limits (requests per minute/hour)
- Daily quota limits on data usage
- Temporary blocks after exceeding limits
Solutions to manage API limits:
- Use built-in rate limiting: Redscraper.io automatically spaces requests to avoid hitting limits.
- Implement retries with delays: When blocked, pause and retry after a cooldown period.
- Distribute requests: Spread scraping tasks over time to reduce bursts of activity.
- Use multiple API keys: Rotate keys to increase total request capacity.
| Problem | Solution |
| Too many requests in a short time | Enable rate limiting and add delays |
| Daily data limit reached | Schedule scraping to the next day or use multiple keys |
| Temporary API block | Pause scraping and retry after cooldown |
Handling Large Data Volumes
Scraping large amounts of Reddit data may cause storage and processing issues. Reddit scraper supports bulk data extraction, but managing the volume is important to avoid crashes or slowdowns.
Challenges with large datasets:
- High memory usage
- Long processing times
- Difficulty organising and analysing data
Ways to handle big data easily:
- Split tasks: Break scraping into smaller batches by date or subreddit.
- Use efficient storage: Save data in compressed files or databases.
- Filter data: Collect only posts and comments that meet your criteria.
- Automate processing: Use scripts to clean and analyse data after scraping.
| Issue | Recommended Approach |
| Memory overload | Scrape in smaller batches and save incrementally |
| Slow data processing | Use automated scripts and efficient data formats |
| Difficulty finding relevant data | Apply filters during scraping to limit data |
Troubleshooting Errors
Errors can occur during Reddit scraping due to connection issues, API changes, or incorrect configurations. Redscraper.io provides tools to identify and fix problems quickly.
Common errors include:
- Connection timeouts
- Invalid API responses
- Authentication failures
- Parsing errors on Reddit data
Steps to troubleshoot effectively:
- Check network connection: Ensure a stable internet connection during scraping.
- Verify API credentials: Confirm your API keys and tokens are valid.
- Update Redscraper.Io: Use the latest version to support Reddit API changes.
- Review error logs: Analyze logs to identify the error source.
- Test with small data: Run sample scrapes to isolate issues.}
Use Cases For Redscraper.io
RedScraper.io simplifies the process of extracting Reddit posts and comments for various practical uses. It allows users to gather large amounts of data quickly and efficiently from Reddit’s vast community discussions. This tool serves multiple purposes across different fields, making data collection straightforward. Below are some common use cases for RedScraper.io that show how it can add value for businesses, researchers, and content creators.
Market Research
Market research depends on understanding customer opinions and trends. RedScraper.io helps by collecting real user discussions from relevant Reddit communities. These conversations reveal what people think about products, brands, and services.
Key benefits for market researchers include:
- Access to authentic feedback: Reddit users often share honest reviews and experiences.
- Trend identification: Spot rising topics and products early through frequent mentions.
- Competitor analysis: Monitor competitor products and customer responses.
Here is a simple table showing how RedScraper.io assists different parts of market research:
| Research Area | How RedScraper.io Helps |
| Customer Insights | Collects detailed comments and posts about products |
| Product Development | Finds user needs and common complaints |
| Competitor Monitoring | Tracks mentions and reviews of competitor brands |
Using RedScraper.io saves time and effort by automating data collection. This allows market researchers to focus more on analysis and strategy.
Sentiment Analysis
Sentiment analysis measures how users feel about a topic. RedScraper.io collects large datasets of posts and comments that reflect public opinion. This data is perfect for analyzing positive, negative, or neutral feelings.
Benefits of using RedScraper.io for sentiment analysis include:
- Large sample size: Gather thousands of posts quickly for accurate results.
- Detailed context: Comments provide explanations behind opinions.
- Real-time monitoring: Track changes in sentiment over time.
Example applications:
- Measuring customer satisfaction for a new product launch.
- Tracking public reaction to news events or policies.
- Analyzing brand reputation based on user feedback.
Sentiment analysis with Reddit data can be done using tools like Python libraries or AI models. Here is a short example of how to load scraped data for sentiment analysis in Python:
import pandas as pd from textblob import TextBlob Load Reddit comments data data = pd.read_csv(‘reddit_comments.csv’) Define a function to get sentiment polarity def get_sentiment(text): return TextBlob(text).sentiment.polarity Apply function to comments column data[‘sentiment_score’] = data[‘comment_text’].apply(get_sentiment) Show average sentiment print(data[‘sentiment_score’].mean())
This code helps convert raw Reddit comments into measurable sentiment scores efficiently.
Content Aggregation
Content aggregation means gathering content from different sources in one place. RedScraper.io collects Reddit posts and comments that fit specific topics or keywords. This helps create focused content hubs without manual searching.
Uses of RedScraper.io for content aggregation include:
- Building niche websites: Collect posts on specific subjects like technology or health.
- Curating newsletters: Find top discussions to share with subscribers.
- Research libraries: Compile user opinions and resources for study.
Benefits of content aggregation with RedScraper.io:
- Automates data collection from multiple Reddit communities.
- Filters content by keywords, date, or subreddit.
- Supports exporting data in formats ready for publishing or analysis.
Here is a sample workflow for content aggregation:
- Use RedScraper.io to scrape posts from targeted subreddits.
- Filter posts by keywords related to your topic.
- Organize content by date or popularity.
- Export content to a CMS or email platform.
This streamlined process saves hours of manual work and keeps content fresh and relevant.
Frequently Asked Questions
What Is Redscraper.io Used For?
Redscraper. Io helps users scrape Reddit posts and comments quickly. It extracts valuable data for analysis, research, or marketing purposes. The tool is user-friendly and requires no coding skills, making Reddit data accessible for everyone.
How Can I Scrape Reddit Posts Easily?
Using Redscraper. Io you can scrape Reddit posts by entering a subreddit or keyword. The platform fetches posts and comments automatically. It saves time and simplifies data collection without manual efforts or complex programming.
Is Redscraper.io Safe And Reliable?
Yes, Redscraper. Io is safe and reliable. It follows Reddit’s API policies and ensures data privacy. The tool maintains high uptime and delivers accurate results, making it trustworthy for scraping Reddit content.
Can I Export Scraped Data From Redscraper.io?
Yes, Redscraper. Io allows you to export scraped Reddit data in formats like CSV or JSON. This makes it easy to analyse or integrate data into other applications or reports efficiently.
Conclusion
Reddit scraper makes Reddit data collection simple and fast. You can gather posts and comments with just a few clicks. This tool helps save time and effort. It works well for research, marketing, or personal use. No special skills are needed to start scraping.
Try Redscraper. io to see how easy scraping can be. Your data gathering will become more efficient and clearer. Give it a shot and enjoy the benefits today.