Businesses handle massive amounts of data every second. From real-time analytics to large-scale data warehousing, processing high-volume data efficiently is crucial. This is where Kafka ETL comes into play. Apache Kafka, an open-source event streaming platform, enables businesses to move, transform, and process high-throughput data in real-time.
This blog explores how Kafka ETL helps manage high-volume data, its advantages, and how integrating it with powerful ETL tools like Hevo Data can further streamline data processing.
A Brief Overview of Kafka ETL
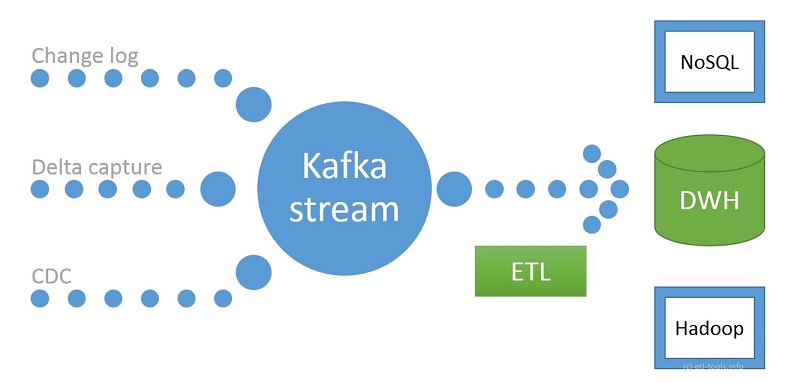
Kafka ETL refers to the process of using Apache Kafka to Extract, Transform, and Load data across different systems. Traditionally, ETL tools followed a batch processing approach, meaning data was extracted, transformed, and loaded at scheduled intervals. However, with the rise of real-time applications, Kafka has become the go-to solution for streaming ETL processes.
Key Components of Kafka in ETL
- Kafka Producers – Extract data from multiple sources (databases, IoT devices, applications).
- Kafka Topics – Store and organize data streams efficiently.
- Kafka Consumers – Process and load data into destination systems.
- Kafka Connect – Enables integration with external databases, cloud storage, and analytics platforms.
Kafka’s distributed architecture ensures fault tolerance, scalability, and real-time processing, making it ideal for high-volume data workloads.
Why is Kafka ETL ideal for High-Volume Data Processing?
1. Real-Time Data Streaming
Kafka’s architecture is designed for continuous data streaming, unlike traditional batch-based ETL tools. Businesses requiring instant insights, such as financial institutions monitoring transactions or e-commerce platforms tracking customer behavior, benefit from Kafka’s ability to process data in real-time.
2. High Throughput and Scalability
Kafka is built to handle millions of events per second without performance degradation. Its distributed nature allows businesses to scale by simply adding more brokers or partitions. This makes Kafka a preferred ETL solution for organizations dealing with extensive datasets.
3. Fault Tolerance and Reliability
Kafka’s data replication mechanism ensures that even if a node fails, data remains available. This built-in fault tolerance is essential for large enterprises where data loss is not an option.
4. Event-Driven Architecture
Kafka operates on an event-driven model, allowing applications to react to data changes in real-time. This is particularly useful in use cases like fraud detection, recommendation engines, and supply chain management, where immediate actions are required.
5. Seamless Integration with Big Data Ecosystem
Kafka integrates with various big data tools such as Apache Spark, Apache Flink, Elasticsearch, and cloud data warehouses. This enables businesses to build complex ETL pipelines without bottlenecks.
Common Use Cases for Kafka ETL
1. Financial Services and Fraud Detection
Banks and fintech companies process millions of transactions daily, making real-time fraud detection essential. Kafka ETL enables continuous monitoring of transactions, allowing financial institutions to detect anomalies and prevent fraud instantly. By analyzing data streams in real-time, suspicious activities—such as unusual spending patterns or unauthorized logins—can be flagged before any damage occurs.
2. E-Commerce and Customer Analytics
Online retailers depend on real-time insights to enhance customer experiences and optimize inventory management. Kafka ETL helps track customer behavior, such as product views, cart additions, and purchases, in real-time. This data allows businesses to personalize recommendations, manage stock levels, and optimize pricing strategies dynamically. Additionally, e-commerce companies use Kafka for demand forecasting and fraud prevention in online transactions.
3. IoT and Sensor Data Processing
IoT devices generate massive volumes of data from smart home appliances, manufacturing sensors, and connected vehicles. Kafka ETL ensures efficient data streaming from these sources, enabling businesses to predict equipment failures, optimize energy consumption, and enhance automation. For example, in predictive maintenance, Kafka helps process sensor readings in real-time, allowing manufacturers to prevent costly breakdowns.
4. Log Monitoring and Security Analytics
Organizations rely on logs to monitor system health, detect cybersecurity threats, and ensure regulatory compliance. Kafka ETL collects, processes, and analyzes logs in real-time, giving IT teams immediate insights into potential security breaches or system failures. This allows quick response to cyber threats, reduced downtime, and improved operational efficiency. Companies in sectors like cloud computing and enterprise IT use Kafka to centralize log management for better visibility and analytics.
By leveraging Kafka ETL for real-time processing, businesses across industries can enhance security, improve customer experiences, and optimize operations—all while handling large-scale data efficiently.
Integrating Kafka with Hevo Data for Optimized ETL Pipelines
While Kafka is powerful for real-time data streaming, integrating it with ETL tools like Hevo Data enhances its efficiency by automating transformation and data loading processes.
Kafka & Hevo Data: A Powerful ETL Combination
- Real-Time Data Processing with Automated Transformations
- Kafka streams high-throughput data, while Hevo Data transforms and structures it in real-time.
- Businesses can apply pre-defined transformations without writing complex code.
- Seamless Data Integration
- Kafka and Hevo Data support integration with cloud data warehouses, databases, and SaaS applications.
- Hevo’s pre-built connectors simplify connecting Kafka to existing infrastructure.
- Scalability for High-Volume Data Loads
- Kafka efficiently ingests large data streams, and Hevo Data ensures scalable transformation and loading into analytical platforms.
- No-Code Data Pipeline Management
- Hevo Data offers a user-friendly, no-code platform that eliminates the complexities of ETL pipeline setup.
- Businesses without dedicated data engineering teams can still manage large-scale data workflows.
Best Use Case for Hevo Data
If your organization requires real-time data integration with minimal manual intervention, Hevo Data is an excellent choice alongside Kafka. It simplifies data transformation, ensuring quick insights and seamless operations.
Challenges of Implementing Kafka ETL
While Kafka ETL is powerful, businesses must address several challenges for smooth implementation:
- Initial Setup Complexity – How to Simplify It
Kafka’s distributed nature requires expertise, but businesses can use managed Kafka services like Confluent Cloud to reduce operational overhead. Additionally, automation tools like Ansible or Terraform help with cluster setup and scaling. - Storage Costs – How to Optimize Retention
Instead of retaining all data indefinitely, businesses should define appropriate retention policies. Kafka’s tiered storage can offload older data to cheaper cloud storage, and using compression techniques (like Snappy or LZ4) helps reduce disk usage. - Data Ordering Issues – How to Maintain Consistency
Since Kafka ensures ordering only within partitions, businesses should design partitions based on keys (e.g., user ID or transaction ID) to maintain order. For strict sequencing across partitions, tools like Kafka Streams or Flink can help reassemble ordered events. - Schema Management – How to Enforce Data Consistency
Implementing Confluent Schema Registry ensures that producers and consumers use consistent data formats. Using Avro or Protobuf instead of JSON minimizes schema drift, making it easier to manage data across multiple Kafka topics.
Despite these challenges, proper planning, robust monitoring, and integration with tools like Hevo Data can streamline Kafka ETL deployment, making it more efficient and cost-effective for businesses handling large-scale data.
Choosing the Right ETL Strategy for Your Business
Before implementing Kafka ETL, consider the following:
- Data Volume & Velocity – If you handle high-throughput data streams, Kafka is a strong choice.
- Real-Time vs. Batch Processing – Kafka excels in real-time; batch-based ETL tools may be better for periodic data loads.
- Integration Needs – Ensure compatibility with cloud platforms, databases, and analytics tools.
- Operational Costs – Factor in infrastructure, storage, and maintenance costs.
- Scalability Requirements – Choose a setup that can grow with your business needs.
Conclusion
Kafka ETL has revolutionized high-volume data processing by enabling real-time streaming, fault tolerance, and scalability. However, businesses must pair it with the right ETL tools—like Hevo Data—to automate transformations, simplify integration, and enhance analytics.For organizations dealing with massive data streams, time-sensitive analytics, or IoT-based workflows, Kafka ETL is a game-changer. By leveraging the right combination of Kafka and Hevo Data, businesses can build efficient, future-proof ETL pipelines tailored to their needs. Schedule a 100% Free Demo with Hevo Data today.